File Processing System With Applications
Table of Contents
A file processing system is a collection of files and programs that access or modify these files. In a file processing system, the record is maintained in different files. All files are separate and not linked with each other. It is an old method of record keeping. To learn more, just read the whole article.
You May Also Like:
- Yolikers APK Download
- 6 Steps of Program Development Process
- Differences B/w Floppy Disk & Hard Disk
- Optical Disk With Applications And Advantages
File Processing System
In the past, several organizations hold on knowledge in files on tape or disk. The info was managed victimization file-processing system. During a typical file process system, every department in a corporation has its own set of files.
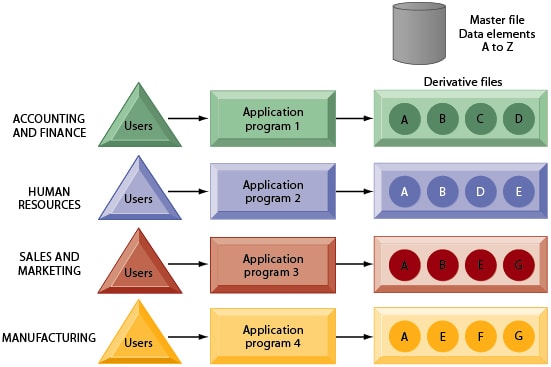
The files area unit is designed especially for his or her own applications. The records in one file don’t seem to be associated with the records in the other file.
Business organizations have used the file-processing system for several years. However, this technique has several disadvantages.
Types of File Organization
Different types of file organization, records are stored one after the other. The records are normally stored in ascending or descending order. This order is based on a value called the key. Key is a field that contains unique data e.g Registration No or NIC No etc.
The value of a key field is different in each record in the file. The records in a sequential file organization are retrieved sequentially. This type of retrieval is known as sequential access. It means that records are accessed one after the other in the same sequence in which they are stored in the file.
The major disadvantage of sequential access is that it is very slow. If the last record is to be retrieved, all preceding record is read before reaching the last record.
Indexed File Organization
In an indexed file organization, records are stored in ascending or descending order. The order is based on a value called key as in a sequential file organization. Additionally, an indexed file organization maintains an index in a file.
An index consists of key values and the corresponding disk address for each record in the file. The index refers to the place on the disk where a record is stored. The index file is updated whenever a record is added or deleted from the file.
When the file is processed, the index is retrieved from the disk and copied to the main memory. The record in an indexed file organization can be accessed sequentially as well as random access or direct access. Direct or random access means that any record can be accessed directly without reading the preceding records.
When a record is to be retrieved, its key value is retrieved from the index file. The index also contains the corresponding address of the disk where the record is stored. This address is then used to access the record on the disk. Direct or random access is faster than sequential access.
Direct File Organization
In direct file organization, the key value of a record is used to determine the location to store the record. Suppose a program establishes a file that has nine locations to store records. If the key in the record is a one-digit value.
This value can be used to specify the location to store that record. For example, the record with key 5 can be stored at relative location 3 and so on. The relative location is also known as a bucket. The implementation of direct file organization becomes complex in some situations.
Suppose the maximum number of records to be stored is 100 and key for a record four-digit number. The four-digit key can give results up to 9999. In this situation, the key cannot be used to specify the relative location. A mathematical formula can be used to find the relative location.
This method is known as hashing. A commonly used hashing technique is called the division/ remainder method. This method uses a prime number that is close to the number of records. It should not be greater than the number of records.
Suppose there are 100 records to be stored. The closest prime number is 97. The key of the record is divided by 97 and the remainder from the division is used as a relative location for storing the record.
Disadvantages of File Processing System
Some important disadvantages of the file processing system are as follows:
Data Redundancy and Inconsistency
In the file processing system, the same data may be duplicated in several files. For example, there are two files “Students” and “Library”. The file “Students” contains the Roll No, name, address and telephone number, and other details of all students in a college.
The file “Library” contains the Roll no and name of those students who get a book from the library along with the information about the rented books. The data of one student appears in two files. This is known as data redundancy. This redundancy causes higher storage.
This situation can also result in data inconsistency. It means that two files may contain different data of the same student. For example, if the address of a student is changed, it must be changed in both files.
There is a possibility that it is changed in the “Students” file and not from the Library file. In this case, the data of the student becomes inconsistent.
Data Isolation
The data in the file processing system is stored in various files. It becomes very difficult to write new application programs to retrieve the appropriate data. Suppose that student emails are stored in the “Students” file and fee information is stored in the “Fee” file.
To send an email message to inform a student that the date for fee payment is over, you need data from both files. In a file processing system, it is difficult to generate such type of list from multiple files.
Integrity Problems
Integrity means reliability and accuracy of data. The stored data must satisfy certain types of consistency constraints. For example, the Roll No and Marks of the students should be a numeric value. It is very difficult to apply constraints on files using the file processing system.
Program Data Dependency
Program data dependency is a relationship between data stored in files and the specific program required to update and maintain those files. With a file processing system, application programs are developed according to a particular file format.
If the format of the underlying file is changed, the application program also needs to be changed accordingly. For example, if there is any change in the length of the postal code, it requires a change in the program. Such changes may be costly to implement.
Atomicity Problem
When you perform an AN operation on knowledge, it’s going to include completely different steps. a set of all steps needed to complete a method is thought of as dealing. The atomicity implies that either one dealing ought to turn up as a full or it shouldn’t turn up in any respect.
Suppose you wish to transfer cash from account A to account B. This method consists of 2 steps:
- Deduct the money from account A
- Add the money to account B
Suppose that the system fails once the pc has performed the primary step. It implies that the quantity has been subtracted from account A, however, has not been else to account B. this case will create your knowledge inconsistently. The file process system doesn’t offer the power to confirm the atomicity of knowledge.
Security Issues
The file process system doesn’t offer adequate security of knowledge. In some things, you will wish to produce different kinds of access permission to knowledge for various users. As an example, a data entry operator ought to solely be allowed to enter data.
The chairman of the organization ought to be ready to access or delete the information fully. Such sorts of security choices aren’t out there in the file process system.
Program Maintenance
The programs developed in the filing process system square measure troublesome to take care of. a great deal of budget is spent on program maintenance. It becomes troublesome to develop new programs






