Types of CPU Scheduling
Table of Contents
A Computer system with a single CPU or a multi-processes system with fewer CPUs has to divide CPU time among the different processes or threads that are competing to use it. This process is called CPU scheduling. Preemptive and Non-preemptive are major types of CPU scheduling.
MultiProgramming
The operating system can make the computer more useful by switching the CPU among multiple processes. The goal of multiprogramming is to hold some processes running at all times. This should make the best use of CPU utilization.
Read Also:
- Chiwi TV APK v9.8 For Android
- Scheduling Algorithms
- Process Scheduling
- Database & Its Component
- Optical Disk With Applications
If there is only one processor (or CPU) then there will only be one process in a running state at any given time. If there are more processes that require to be run, they will have to stay and wait. There must be some mechanism to select which process (currently in memory) will run next when the CPU becomes available.
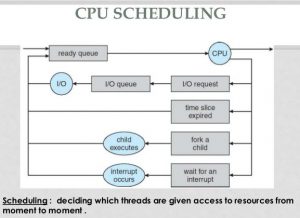
The operating system maintains a ready queue. All the processes in this queue are in a standby position to be executed. Whenever a currently executing process needs to wait (does I/O etc.), the operating system picks a process from the ready queue and assigns the CPU to that process.
Scheduling is a fundamental operating system function. CPU is an important resource. So, it is very important to build up good scheduling algorithms.
Suppose we have two processes A and B to be executed. Each and every process executes for one second then holds for one second. It is repeated 60 times. If we run process A first and then process B, one after the other, it will take four minutes to run the two processes:
A takes two minutes to run and then B acquires two minutes to run. We in fact compute only two minutes of this time. The remaining two minutes are inoperative time. Our CPU utilization is only 50%.
CPU Scheduling Objectives
Schedulers normally try to achieve some mixture of the following goals. These goals are conflicting to some level:
- Make the best use of CPU utilization (due to its relatively high cost)
- Maximize the consumption of other resources (disks, printers, etc.)
- Maximize throughput = number of jobs completed per unit time.
- Decrease waiting time = total time a job spends waiting in the different queues for a resource to become accessible.
- Minimize rotate time = waiting time + computation time + I/O time
- Reduce response time (timesharing) = time from entry of command until the first output starts to appear.
- Fairness: all similar jobs should be treated likewise.
- Avoid indefinite postponement. It is normally avoided by using aging. In aging, the priority of a process grows as it waits for a resource. The priority slowly becomes highest and it gets the resource.
- Uniformity: the behavior of the system should be predictable.
- Graceful degradation: the system response deteriorates gradually rather than coming to a sudden virtual standstill in case of excessive loads.
- Predictability: a given job should run in about the same amount of time and at about the same cost regardless of system load.
Working of CPU Scheduler
The process to choose the next job that will run on the CPU belongs to the short-term or CPU scheduler. The CPU scheduler can only select from the jobs that are already in memory and prepared to go. The scheduler works in cooperation with the interrupts system.
- The scheduler assigns the CPU to act upon calculation on behalf of a specific process or thread within a process.
- CPU can be rented from its present process by an interrupt. It is in the control of external devices, not the scheduler. Interrupts can be disabled for a short time.
- When a process or thread desires an I/O transfer, it usually becomes unable to use the CPU until the transfer is complete. This means that the scheduler will have to select a new process or a new thread within the same process to use the CPU.
- The process of thread that requested the I/O again becomes eligible to use the CPU when the I/O transfer is complete.
Types of CPU Scheduling
Major types of CPU scheduling are preemptive and Non-Preemptive. In Preemptive scheduling, a process may be removed from the CPU by force even it does not want to release the CPU when a higher priority process needs the CPU.
Whereas, in Non-Preemptive scheduling, a higher priority process waits for a currently running process to finish regardless of the priority e.g FCFS. Normally, there are four types of CPU scheduling:
- Preemptive Scheduling
- Non-preemptive Scheduling
- Multiple Processor scheduling
- Real-Time scheduling
Preemptive and Non-preemptive CPU Scheduling
There are four conditions under which the above types of CPU scheduling may take place. They are:
- When a process switches from the running state to the waiting state.
- The second is when a process switches from the running state to the ready state.
- When a process switches from the waiting state to the ready state.
- When a process terminates.
If only one condition 1 and 4 apply, the scheduling is called non-preemptive. All other types of CPU scheduling are preemptive. Preemptive means that a process may be forcibly removed from the CPU even if it does not want to release the CPU.
It is because a higher priority process needs the CPU. Once a process gets CPU, the simplest approach is to allow the process to continue using CPU until it voluntarily yields CPU by requesting an I/O transfer, etc. I/O interrupts may steal CPU from time to time.
After each interrupt, control passes back to the process that was running when it occurred. This is called a non-preemptive approach.
In a preemptive scheme, a running process may be forced to yield CPU by an external event instead of its own action. Such external events can be any or both of the following:
- A higher priority process enters the system from outside.
- A higher priority process that was in the wait state becomes ready. This could occur as the result of an I/O interrupt that moves as the waiting process to the ready list.
Interval Timer
Timer interruption is a technique that is strongly interrelated to preemption. When a process acquires the CPU, a timer may be set to a specific period. If the process is still using the CPU at the end of the period, then it is preempted.
Both timer interruption and preemption force a process to yield the CPU before its CPU burst is complete. However, it is helpful to distinguish timer interruption from preemption caused by higher priority processes becoming ready for two reasons:
- Timer interruption is a function of the particular process’s own behavior. It is independent of the rest of the system.
- Almost all multi-programmed operating systems use some form of a timer to prevent a process from tying up the system forever. But preemption for a higher priority process is a quality that may or may not be integrated into a given operating system.
Dispatcher
The dispatcher is a program that actually gives control of the CPU to a process selected by the CPU scheduler. It is another part of the scheduling system.
The functions of the dispatcher module are as follows:
- Switching context
- Switching to user mode
- Jumping to a suitable location in the user program to restart it
The dispatcher should be very fast because it is called every time a process takes control of the CPU. The time that the dispatcher takes between stopping one process and starting another process is called dispatch latency.
CPU Scheduling Criteria
There are a lot of scheduling algorithms and a variety of criteria to judge their performance. Different algorithms may support different types of processes. Some criteria are as follows:
- CPU utilization: CPU must be as busy as feasible in performing diverse tasks. The CPU utilization is very important in real-time systems and multi-programmed systems.
- Throughput: the quantity of processes executed in a specific time period is called throughput. The throughput increases for short processes. It decreases if the size of the processes is huge.
- Turnaround time: the amount of time that is needed to perform a process is called turnaround time. It is the actual job time plus the waiting time.
- Waiting time: the sum of time the process has waited is called waiting time. It is the turnaround time minus actual job time.
- Response time: the amount of time between a request is submitted and the first response is produced is called response time.
A CPU scheduling algorithm should try to reduce the following:
- CPU utilization
- Throughput
A CPU scheduling algorithm should try to decrease the following:
- Turnaround time
- Waiting time
- Response time
Multiple Processor CPU scheduling
CPU scheduling becomes much more complex when multiple CPUs are available. It is now possible for more than one job to run on a machine at any one time. The number of running jobs is equal to the number of processors.
An important issue is access to resources. Suppose only processor A has access to a certain device. others cannot access that device. any process that requires that devices have to be scheduled on processor A as other processors cannot satisfy its requests.
Another issue is that of contention. If two processes run on separate processors, they may try to update some shared data. It is also possible that two processors may try to grab the same process from the ready queue.
Some systems assign one master processor to do all the scheduling work. The master processor hands out the work to the slave processors who actually do the work. This ensures that there is only one processor responsible for scheduling work.
It should have all the information required to properly perform the scheduling. This approach requires no data sharing between processors.
Real-Time CPU scheduling
There are two types of real-time systems:
- Hard Real-Time Systems
- Soft Real-Time Systems
Hard Real-Time Systems
The scheduler must ensure that a task is completed within a guaranteed amount of time.
Soft Real-Time Systems
The scheduler must ensure that the higher priority processes will run first. There is no guarantee that the process will finish within a specified time limit. The only guarantee is that the process will finish as soon as possible.
Algorithm Evaluation
There are a number of scheduling algorithms and strategies. The choice of algorithm depends heavily on the most important criteria. Once an algorithm is selected, it should be evaluated. Here are some ways to evaluate an algorithm:
Deterministic Modeling
It takes a particular predetermined workload and defines the performance of the algorithm depending on that workload. This form of evaluation is simple and can be done quickly. However, it is not very general. We might get a completely different idea about the performance of an algorithm if we chose a different set of processes.
Queuing Models
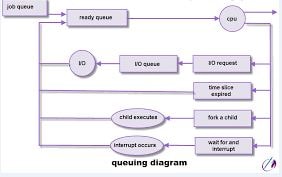 We can examine the distribution of CPU burst and I/O wait times. We can apply a formula and compute one of three things
We can examine the distribution of CPU burst and I/O wait times. We can apply a formula and compute one of three things
- The average length of the queue
- Average waiting time of the queue
- Average arrival rate
This approach does have some limitations. For example, the results may not be very exact as they rely on an approximation of the actual system.
Simulation
A lot of processes are required to simulate an operating system. The processes should mimic those of typical users and the operating system itself that can be difficult. The simulation may take a long time to complete. For more accurate results, it may be necessary to use process information from a real system.
Implementation
The only real way to test an operating system is to write the code and run it. However, this approach is very expensive.






